Quick answer, here are the headline prices per 1M tokens:
Opus 4.1, input $15, output $75, prompt caching write $18.75, read $1.50
Sonnet 4.5
prompts up to 200k tokens, input $3, output $15, caching write $3.75, read $0.30
prompts over 200k tokens, input $6, output $22.50, caching write $7.50, read $0.60
Haiku 4.5, input $1, output $5, prompt caching write $1.25, read $0.10
But If you have ever looked at an AI bill and thought, what on earth is a token? This guide is for you. We will keep it friendly, do round-number math, and show how Anthropic charges for Claude models for API that you can use in your applications.
API vs Claude web subscription
Claude web plan, fixed monthly fee, good for chatting in the product. No per-message billing.
Anthropic API, pay for what your app sends in and what it gets back. The meter is in tokens.
Use the API when your bot or workflow calls Claude programmatically.
What are tokens?
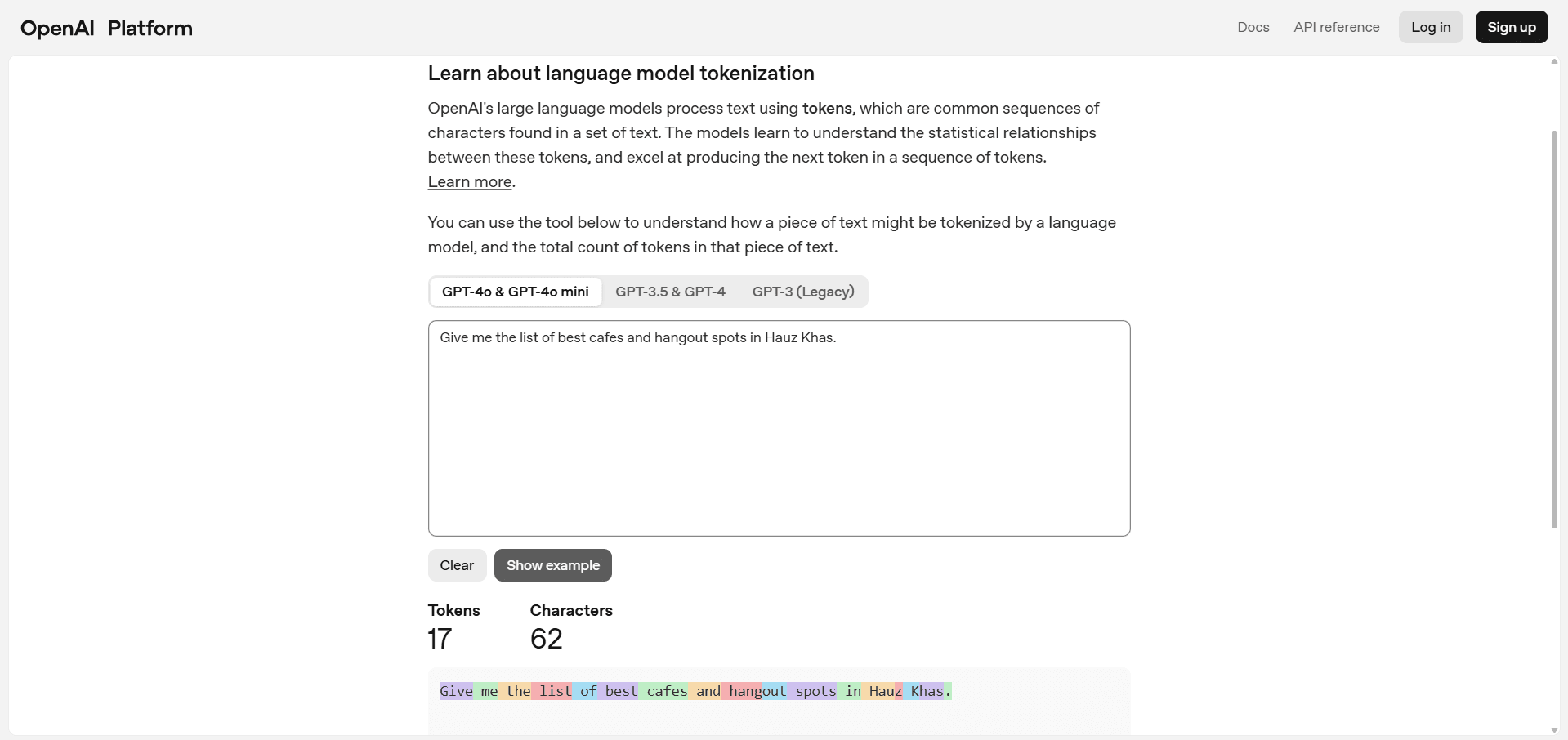
A token is a small piece of text. Think of 1,000 tokens as about 750 words of English. You can see the conversion from a prompt/response (any block of text) to tokens on Open AI's Tokenizer Platform.
Your cost has two parts:
Input tokens – what you send in, for example system prompt, instructions, user text
Output tokens – what the model writes back
Output is priced higher than input on most models, so long answers cost more than short ones.
Claude model prices (per 1M tokens)
| Model | Input | Output | Prompt caching write | Prompt caching read |
|---|---|---|---|---|
| Opus 4.1 | $15 | $75 | $18.75 | $1.50 |
| Sonnet 4.5, prompts ≤ 200k | $3 | $15 | $3.75 | $0.30 |
| Sonnet 4.5, prompts > 200k | $6 | $22.50 | $7.50 | $0.60 |
| Haiku 4.5 | $1 | $5 | $1.25 | $0.10 |
Prompt caching means if a repeated chunk of your prompt is cached, the cached part is billed at the lower write or read rate. Think of a long system prompt you reuse on many calls. For quick estimates you can ignore caching.
The cost formula
Total cost
= input_tokens × input_price_per_token
+ cached_input_tokens × cached_price_per_token
+ output_tokens × output_price_per_token
Price per token is the “per 1M” number divided by 1,000,000.
Examples with the math
1) Small chat on Haiku 4.5
Prompt 800 tokens, reply 300 tokens
Input, 800 × $1/10^6 = $0.0008
Output, 300 × $5/10^6 = $0.0015
Total, $0.0023 per call, that is 0.23 cents
50,000 such calls in a month ≈ $115 (~ ₹ 11,000)
2) Long reply on Opus 4.1
Prompt 5,000 tokens, reply 2,000 tokens
Input, 5000 × $15/10^6 = $0.075
Output, 2000 × $75/10^6 = $0.150
Total, $0.225 per call
1,000 calls like this ≈ $225 (~ ₹ 20,000)
How to keep API costs low?
Keep answers tight, output costs more than input on most models.
Pick the right model
Use Haiku for high volume tasks, summaries, tagging.
Use Sonnet for most app features and agents.
Use Opus only when you need extra skill, for example tricky planning or code.
Cache repeat text like long system prompts.
Control max output with a sensible cap on output tokens.
Which Claude model should I use?

Start with Haiku, cheap and fast for bulk work.
Move to Sonnet when you need stronger reasoning or tool use.
Use Opus for the hard stuff only, where it clearly wins in your tests.
Where to use Claude's API?
Claude's API is an extremely powerful tool for all businesses. Your business can stay ahead of the curve by integrating this API on your business' WhatsApp number, using it to answer your customers queries in a jiffy. Heltar does that for you with a quick and easy setup, for just a small fee, without any markup on the OpenAI cost.
Heltar is a WhatsApp Business API provider built for these needs.
Shared inbox, roles, and assignments so sales can work from one place.
Automation inside the inbox, plus quick setup for keywords, menus, and forms. You can create a WhatsApp chatbot using a drag-and-drop, no-code chatbot builder. Just one AI prompt, and you have your automation ready to be deployed. You can't get this luxury on Zapier.
Template workflows for approval, variables, and safe bulk sends. You create templates and get them approved within seconds, ready to be launched as part of bulk messaging campaigns.
24-hour window guardrails that auto enforce message type rules.
Campaigns and segments with schedules and rate control. Schedule and Fire any campaign in less than a minute, marketing made simple!
Live reports for delivery, reads, failures, leads, and outcomes.
If this is what your business needs, reach out to us for a demo today!